Another source of information that can help in determining a match is the matching status of neighbouring blocks. There is no reason to believe that matching data in the target file will end neatly on block boundaries - quite the opposite, we will expect to see that after one block matches, neighbouring blocks of the source data will match corresponding neighbours in the target data, giving long areas in the source file that can be copied to the target file.
One way to use this is by rejecting matches unless a certain number of consecutive neighbouring blocks also match (see [[CIS2004]]). If we insist on, say, 2 matching blocks in sequence, we greatly reduce the chance of false positives - assuming the checksums of these blocks remain independent, then we can halve the number of bytes of strong checksum transmitted per block. The only matches we lose by this restriction are single-block matches - but these are rare anyway, and are the least serious matches to miss (because we will normally have unmatched data either side that needs to be fetched, so the loss of transmitting the data for the extra block is partially offset by the reduced overhead of downloading a single range instead of the two ranges either side). (Alternatively, one can think of this as splitting a larger matching block into two parts and allowing half-block aligned matches, as discussed in [[CIS2004]].)
The first match of a sequence will involve two neighbouring blocks matching together; assuming this is equivalent to a single block matching with the hash lengths combined, then we can directly halve the required checksum bits from the previous section. For subsequent blocks, while we are testing with a reduced hash length, we are only testing against a single, specific location in the target file, so again the chance of a false match is reduced. So, to avoid false positives in these two cases, we must have enough hash bits to satisfy the following two conditions:
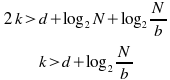
(from [[CIS2004]]; I have checked that this seems right, but haven't verified in detail)
At the block sizes that zsync uses, the latter inequality is usually the stricter one, but the difference is small, so the saving in transmitted data is near, if not quite, 50%. For zsync in particular — which, unlike rsync, must always calculate and transmit the strong checksum data for every block in the target file — this is a worthwhile saving.
Note that we can also reduce the amount of weak checksum data transmitted, by assuming that matches for consecutive blocks are needed - in testing it proved more efficient to calculate the weak checksum for both blocks, rather than testing the weak checksum of only the first and then calculating the strong checksum for both (because in a situation where a given block occurred very often in a file, for example an all-null block in an ISO image, a prior block match provides much weaker information about the likelyhood of a following block match). Once we are calculating both weak checksums, we can halve the amount of weak checksum data transmitted. In testing this was upheld, and checking both weak checksums did not significantly harm performance, while providing a definite reduction in the metadata transferred.