For now, let us restrict ourselves to deflated files. By this I mean the deflate algorithm as defined in RFC1951, and implemented in zlib and in the popular gzip format on Unix systems. More complex formats, like zip files, would introduce too much complexity into the client, as it is unclear what one would do with the uncompressed stream corresponding to such a file: it needs the metadata from the compressed archive to be useful. Simple deflated streams are ideal, in that the compressed file wrapper contains no information of interest to us, so we can ignore it and look at only the stream of data that it contains.
We have some blocks of data from the uncompressed file locally; we want the remaining blocks from the server; the server offers only the deflated stream and only allows us to access it at offsets in the deflated stream. We cannot read the entire compressed stream from the server, because that means there is no use knowing any data locally. So we must have a map which allows us to work out where in the deflated stream a given block of the underlying uncompressed data is — and enough data to allow us to pull this data out of the middle of the deflated stream and inflate it.
This information is available at the time that the zsync metadata is calculated. The program to write the block checksums can also record the location in the deflated stream where a given block occurs. This is not enough by itself, however. The deflate algorithm works by writing data out in blocks; each block's header indicates either that the block is merely stored (so that blocks of data that do not compress well are stored as-is in the gzip file), or it gives the code lengths and other data needed to construct the decoding tree. A typical deflate program like gzip will calculate the optimum compression codes as it goes along, and will start a new block with new codes whenever it calculates that the character distribution of the data stream has altered enough to make a change in the encoding worthwhile. We cannot merely retrieve the compressed data at a given point: we must also have the preceding block header, in order to construct the decoding tree.
So we construct a table that contains the offset of each block header in the deflated stream, and the offset in the uncompressed data that this corresponds to. We can also store similar offset pairs away from block headers, but the client will need to get the preceding block header before it can use one of these.
A simple implementation on the client side can then work out, for each block of data that it needs, which block(s) in the deflated data contains it. It then retrieves these blocks and inflates them, and takes out the chunk of data that it wanted. It will end up transferring the whole deflated block, which will contain more data than it needs — but it will benefit from the data being compressed. The client must also be intelligent about spotting overlaps and merges in the ranges to be retrieve: for instance, two non-adjacent blocks from the uncompressed stream might lie in the same deflate block, or in adjacent deflate blocks, so the client should retrieve a single range from the server and decompress it in one pass. zsync-0.0.1 up to zsync-0.1.0 implemented this approach.
A more sophisticated implementation can use the pointers within blocks. In order to decompress part of the stream, we need to know: the header for the block (or its location in the file, so we can download it); an offset into the compressed stream for that block (which is an offset in bits, as the gzip format used variable-length codes); and a number of leading bytes of output to skip (because it may not be possible to provide an index in the compressed stream corresponding to the desired offset in the uncompressed stream, for example when a backreference generates several bytes of output for a single compressed code). Given this information, we can download the header and the relevant section from the compressed stream, and inflate it; it is no longer necessary to download the whole compressed block.
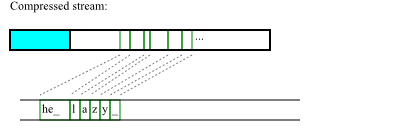 |
This image illustrates a hypothetical compressed stream for "The quick fox jumped over the lazy dog.", showing the inflated version of part of the stream (underscores are used to denote spaces in this, for clarity). Note that the first compressed code shown expands to 3 characters, "he " (it is a backreference to the occurrence of the same 3 characters earlier in the sentence).
To extract a block starting at "e lazy dog.", we need to know the offset of the code containing the backreference for "he " in the compressed stream, and the offset at the end of the block, so that we can download the compressed data; and the offset (1 character) from the start of "he " to the character we want; and the location of the block header (shown in blue).
There is a final difficulty with deflate streams: backreferences. Deflate streams include backwards references to data earlier in the stream within a given (usually 32Kb) window, so that data need not be duplicated. The zsync client will need to know 32Kb of data of leading context before trying to inflate any block from the middle of the deflate stream. Provided the zsync client requests blocks in order, it can inductively guarantee that it knows all prior content, and so can construct the window required by the inflate function.
zsync-0.1.2 and up have implemented this more sophisticated algorithm. The zsyncmake program constructs a sufficiently detailed map of the compressed file so that zsync can download only the parts of compressed blocks that it needs.